
Introduction
It is very easy to write your own server side connector. One of the strengths of the ES is the ability to write your own connectors in Perl, which run directly on the ES server. These connectors only needs to download the data from the source, then all data converting will be handled by the ES.
The ES crawler API
The ES connector API require you to make a Perl package that exports at least the subroutine crawl_update().
crawl_update() is called at regular intervals to see if it is any new data available. It shall inspect its source data and determents if new data have arrived. If so, it uses add_document() to add it to the search index.
The data added to the ES is always referred to as a “document”, regardless of type and source.
More information on the api is available at /wiki/Category:Perl_connectors .
Example 1: A Twitter connector using the Twitter json API and Perl
This example will show you how to make a custom connector for the ES. We will be crawling Twitter, a public data source, so we don’t have to worry about end-user authenticating and the uend-users permissions on the data, but you will have to authenticate with Twitter to access the json feed.
Twitter has an http api where you can see the latest twits for a user. This is done by crafting a special url in the format http://api.twitter.com/1.1/statuses/user_timeline/{USER}.{FORMAT}. For example CNN Breaking News have twiter page http://twitter.com/cnnbrk . Making Rss and Json available from the following url's :
More info about the Twitter api is available at https://dev.twitter.com/docs/api/1.1/get/statuses/user_timeline .
Getting startet
Start by selecting the “Connectors” section in the ES admin. Then create a new connector by clicking on the “Create a new connector” button.
The new connector will be issued a default name. So our first step is to change this to something reasonable. At the settings and parameters tab, set name to “MyTwitter” and click the “Update” button.
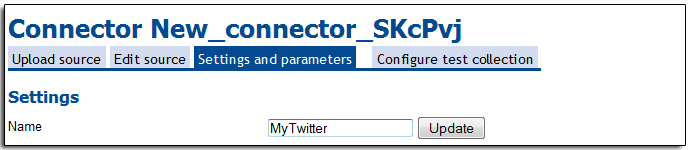
To make this connector as general as possible we are going to have with twitter screen name to index as an parameter. To do so we must first go to the settings and parameters tab and add a parametes called “screen name” for choosing witch Twitter screen name to crawl, select authentication as an anput field also.
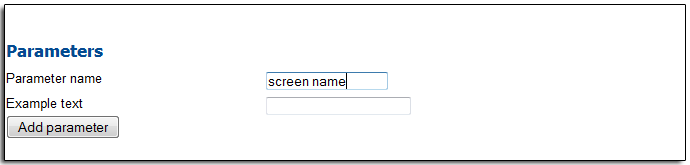
At the configure test collection tab, set screen name to the twitter screen name you want to crawl. In this case CNN Breaking News screen name “cnnbrk”.
Usage of the Twitter api also require that your authenticate. Your “Consumer key” will be your username, and your “Consumer secret” will be your password. If you don’t have a Consumer key and secret go to https://dev.twitter.com/apps to log in with your Twitter id and add a new application.

The code
Then go to edit source tab where we will write the actual sorce code. The ES will have filed in some example code, but we don’t need that now. So start with removing all source code in crawl_update() so you get a clean routine like this.
sub crawl_update {
my (undef, $self, $opt) = @_;
};
The $opt variable is a hash reference containing all input options. For example the screen name we configured above will be at $opt->{'screen name'} . You can see the content in $opt by adding the following line to crawl_update().
warn "Options received: ", Dumper($opt), "\n";
At this point it's smart to test that the framework is working as exspected. Update the crawl_update() so you get:
sub crawl_update {
my (undef, $self, $opt) = @_;
warn "Options received: ", Dumper($opt), "\n";
};
Then click the save and run button below the code window.

The errors about mysql and bbdn can safely be ignored. You are not using threads and persistent bbdn connection.
Implementing
Back at the edit source window we can start to implement the Twitter connector.
We will be using the Cpan modules JSON::XS, use Date::Parse; and LWP::Simple in this connector. So first we add refferanses to them at the top of the source just below the other "use" and our statements.We gets:
use Crawler; our @ISA = qw(Crawler); use JSON::XS qw(from_json); use Date::Parse; use HTTP::Request; use MIME::Base64; use LWP::UserAgent;
Then we wil modefy crawl_update() to crawl Twitter.
First we will have to authenticate with Twitter.
# Setup user agent
my $userAgent = LWP::UserAgent->new();
$userAgent->timeout(30);
# Autenticat with twitter
my $request = new HTTP::Request( 'POST', 'https://api.twitter.com/oauth2/token' );
# Setup the correct content type for the post.
$request->content_type('application/x-www-form-urlencoded;charset=UTF-8');
# Setup the your keys
$request->authorization_basic( $opt->{'user'}, $opt->{'password'} );
# Setup the message you wish to send.
$request->content( 'grant_type=client_credentials' );
# Now we pass the request to the user agent to get it fetched.
my $response = $userAgent->request($request);
if( !$response->is_success ) {
die "Unable to connect to Twitter: " . $response->status_line;
}
my $tout = from_json($response->content);
my $token = $tout->{access_token};
We then build the url to the json feed. Then uses get() and from_json() to download and decode it.
my $jurl = "https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name=" . $opt->{'screen name'};
# Ask twitter for the users timeline
$request = HTTP::Request->new( 'GET', $jurl );
# Add Authorization header value
$request->header( 'Authorization' => "Bearer " . $token);
# Now we pass the request to the user agent to get it feched.
my $response = $userAgent->request($request);
if( !$response->is_success ) {
die "Unable to connect to Twitter: " . $response->status_line;
}
my $t = from_json($response->content);
Finally we loop thru the json data, format it correctly, and submit is to the ES.
for my $usr (@{$t}) {
my $content = $usr->{text};
my $url = "http://twitter.com/" . "$usr->{user}{screen_name}/statuses/$usr->{id}";
next if $self->document_exists($url, 0);
my $substr = substr($content, 0, 50);
my $title = "$usr->{user}{name}: $substr ..";
my $created_at = str2time($usr->{created_at});
warn "Adding $title";
$self->add_document((
content => $content,
title => $title,
url => $url,
type => "tapp",
acl_allow => "Everyone",
last_modified => $created_at,
));
}
Click Save and Run. Hopefully you will see something like this.

If you have a user system setup (for example Microsoft Active Directory) you have to enable anonymous search of this collection. Go to the Settings and parameters and select accesslevel as a input field. Then at the Configure test collection tab set accesslevel to "Anonymous". If you don't have a user system then the collection is set to anonymous access as default, so no more configurations are necessary.
Finaly click on the Public search page button in the left top corner and you will se the search page. Search for something.

Full code
package Perlcrawl;
use Carp;
use Data::Dumper;
use strict;
use warnings;
use Crawler;
our @ISA = qw(Crawler);
use JSON::XS qw(from_json);
use Date::Parse;
use HTTP::Request;
use MIME::Base64;
use LWP::UserAgent;
##
# Main loop for a crawl update.
# This is where a resource is crawled, and documents added.
sub crawl_update {
my (undef, $self, $opt) = @_;
warn "Options received: ", Dumper($opt), "\n";
# Setup user agent
my $userAgent = LWP::UserAgent->new();
$userAgent->timeout(30);
# Autenticat with twitter
my $request = new HTTP::Request( 'POST', 'https://api.twitter.com/oauth2/token' );
# Setup the correct content type for the post.
$request->content_type('application/x-www-form-urlencoded;charset=UTF-8');
# Setup the your keys
$request->authorization_basic( $opt->{'user'}, $opt->{'password'} );
# Setup the message you wish to send.
$request->content( 'grant_type=client_credentials' );
# Now we pass the request to the user agent to get it fetched.
my $response = $userAgent->request($request);
if( !$response->is_success ) {
die "Unable to connect to Twitter: " . $response->status_line;
}
my $tout = from_json($response->content);
my $token = $tout->{access_token};
my $jurl = "https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name=" . $opt->{'screen name'};
# Ask twitter for the users timeline
$request = HTTP::Request->new( 'GET', $jurl );
# Add Authorization header value
$request->header( 'Authorization' => "Bearer " . $token);
# Now we pass the request to the user agent to get it feched.
my $response = $userAgent->request($request);
if( !$response->is_success ) {
die "Unable to connect to Twitter: " . $response->status_line;
}
my $t = from_json($response->content);
for my $usr (@{$t}) {
my $content = $usr->{text};
my $url = "http://twitter.com/" . $usr->{user}{screen_name} . "/statuses/" . $usr->{id};
next if $self->document_exists($url, 0);
my $substr = substr($content, 0, 50);
my $title = "$usr->{user}{name}: $substr ..";
my $created_at = str2time($usr->{created_at});
print "Adding $title\n";
$self->add_document((
content => $content,
title => $title,
url => $url,
type => "tapp",
acl_allow => "Everyone",
last_modified => $created_at,
));
}
};
sub path_access {
my ($undef, $self, $opt) = @_;
# During a user search, `path access' is called against the search results
# before they are shown to the user. This is to check if the user still has
# access to the results.
#
# If this is irrelevant to you, just return 1.
# You'll want to return 0 when:
# * The document doesn't exist anymore
# * The user has lost priviledges to read the document
# * .. when you want the document to be filtered from a user search in general.
return 1;
}
1;
Download the full source code at: Simple Twitter connector.txt
Example 2: Using attributes
Often you will like to add meta information to the data you index. In the ES connector framwork we call this "attributes". For example below is a search hit where a twitt is marked with the Twitter id and the name of the person (or organisation) that made the twitt.

This information can also bee summarised in the navigation menu.

To do this we will extend our code to support indexing multiple twitter accounts, and add Person and Twitter id attributes.
Multiple accounts
To support multiple accounts we will change the input parameter to take inn a comma separated list of Twitter ids. Then split the list and go thru one and one like we did before.
my @twitters = split(',', $opt->{'screen name'});
foreach my $screenname (@twitters) {
#get json and add to ES
}
At the Configure test collection tab change the screen name parameter to a comma separated list of Twitter accounts you want to index. For example "cnnbrk,BBCNews,CBSNews".
Adding attributes
The add_document() expects the attributes to be a Perl hash.
$self->add_document((
content => $content,
title => $title,
url => $url,
type => "tapp",
acl_allow => "Everyone",
last_modified => $created_at,
attributes => {
'Person' => $usr->{user}{name},
'Twitter id' => $usr->{user}{screen_name}
}
));
Most attributes are just shown in the search hit, but if the attributes is one of Appointment, Customer, Document, Selection, Person, Project or Sale it is also automatically added to the filer menu as an information type.
Full code
package Perlcrawl;
use Carp;
use Data::Dumper;
use strict;
use warnings;
use Crawler;
our @ISA = qw(Crawler);
use JSON::XS qw(from_json);
use Date::Parse;
use HTTP::Request;
use MIME::Base64;
use LWP::UserAgent;
##
# Main loop for a crawl update.
# This is where a resource is crawled, and documents added.
sub crawl_update {
my (undef, $self, $opt) = @_;
warn "Options received: ", Dumper($opt), "\n";
# Setup user agent
my $userAgent = LWP::UserAgent->new();
$userAgent->timeout(30);
# Autenticat with twitter
my $request = new HTTP::Request( 'POST', 'https://api.twitter.com/oauth2/token' );
# Setup the correct content type for the post.
$request->content_type('application/x-www-form-urlencoded;charset=UTF-8');
# Setup the your keys
$request->authorization_basic( $opt->{'user'}, $opt->{'password'} );
# Setup the message you wish to send.
$request->content( 'grant_type=client_credentials' );
# Now we pass the request to the user agent to get it fetched.
my $response = $userAgent->request($request);
if( !$response->is_success ) {
die "Unable to connect to Twitter: " . $response->status_line;
}
my $tout = from_json($response->content);
my $token = $tout->{access_token};
my @twitters = split(',', $opt->{'screen name'});
foreach my $screenname (@twitters) {
my $jurl = "https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name=" . $screenname;
# Ask twitter for the users timeline
$request = HTTP::Request->new( 'GET', $jurl );
# Add Authorization header value
$request->header( 'Authorization' => "Bearer " . $token);
# Now we pass the request to the user agent to get it feched.
my $response = $userAgent->request($request);
if( !$response->is_success ) {
die "Unable to connect to Twitter: " . $response->status_line;
}
my $t = from_json($response->content);
for my $usr (@{$t}) {
my $content = $usr->{text};
my $url = "http://twitter.com/" . $usr->{user}{screen_name} . "/statuses/" . $usr->{id};
next if $self->document_exists($url, 0);
my $substr = substr($content, 0, 50);
my $title = "$usr->{user}{name}: $substr ..";
my $created_at = str2time($usr->{created_at});
print "Adding $title\n";
$self->add_document((
content => $content,
title => $title,
url => $url,
type => "tapp",
acl_allow => "Everyone",
last_modified => $created_at,
attributes => {
'Person' => $usr->{user}{name},
'Twitter id' => $usr->{user}{screen_name}
}
));
}
}
};
sub path_access {
my ($undef, $self, $opt) = @_;
# During a user search, `path access' is called against the search results
# before they are shown to the user. This is to check if the user still has
# access to the results.
#
# If this is irrelevant to you, just return 1.
# You'll want to return 0 when:
# * The document doesn't exist anymore
# * The user has lost priviledges to read the document
# * .. when you want the document to be filtered from a user search in general.
return 1;
}
1;
Download the full source code at: Simple Twitter connector - with attributes.txt
Interacting directly with the ES
While the webgui is nice for doing small tasks and adding a line or two of code, you will probably need more direct access to the ES to do real work. First we will need ssh access to log in.
Getting ssh access for the “boitho” user
Step 1. Setting a password for the boitho user
Log on the the ES as root and execute:
passwd boitho
Follow the instructions on the screen to setup a password.
Step 2. Configure ssh
Open the file /etc/ssh/sshd_config and find whers it sess "PasswordAuthentication no" and change it to "PasswordAuthentication yes".
nano /etc/ssh/sshd_config
Restart ssh:
/etc/init.d/sshd restart
You should now be able to login using the password you provided in step 1.
Tip: There is both an /etc/ssh/sshd_config and a /etc/ssh/ssh_config file. You should edit the one with a "d".
Running the crawler from the connsole
First stop the crawler by execute:
/etc/init.d/crawlManager stop
To correctly execut the crawler you need to setup the BOITHOHOME environmental path and be in the correct folder. So
export BOITHOHOME=/home/boitho/boithoTools cd /home/boitho/boithoTools/
You can then run it with:
bin/crawlManager2
You can then sent command to the crawler to recrawl, crawl, delete etc from the web based administration interface. Be aware that this only work with crawlers that you run from the main "Overview" part of the administration interface. Crawling jobs you run from the "Connectors->Modify" will redirect output to the administration interface, and show nothing on the console.
Perl based crawlers is located as a file called main.pm in the folder /home/boitho/boithoTools/crawlers/[crawler name]/ . For example you MyTwitter crawler from the "Example: A Twitter connector" article above, should be in /home/boitho/boithoTools/crawlers/MyTwitter/main.pm . If you set the file permissions to 777 you can edit it using your favorite text editor from the console.
su - chmod 777 /home/boitho/boithoTools/crawlers/Zendesk/main.pm exit
Working with text. Use UTF-8
All text and html data you index in the ES should be in UTF-8. If you ever see texts looking like this:
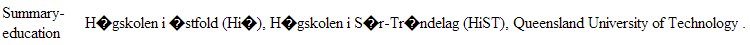
Insted of this:
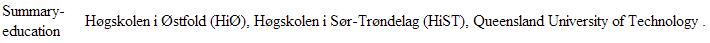
You have probably indexed some latin-1 or other unsupported encoding. In the Perl crawler use the Encode module to encode your text to UTF-8 before indexing it.
Example:
use Encode qw(decode encode);
$text = encode('UTF-8', $text, Encode::FB_CROAK);
More information is available in the Perl documentation at the Encode - character encodings in Perl section.
Running Perl from the connsole
The embedded version the ES is using is 32 bit version of Perl. But /usr/bin/perl is 64 bit. You may therefor experiences some differences in available CPAN modules if you develop scripts from the command line, and then later embed them in the crawler or usersystem. To run Perl with the same environment and with the same modules as the ES , use the /home/boitho/boithoTools/bin/perl binary.
Installing CPAN modules
Please see her for documentation on how to install CPAN modules: https://github.com/searchdaimon/enterprise-search/wiki/Installing-Perl-CPAN-modules